
1. 显存的三个概念:
SM(Streaming Multiprocessor):SM是GPU实际计算单元。
GPU HBM(High Bandwidth Memory):HMB就是我们平时所说的显存,空间(相对)大,但数据传输带宽(相对)低。
GPU SRAM(Static Random Access Memory):SRAM是一种高速运行的存储器,通常用于GPU内部的缓存,如L1和L2缓存。SM依赖SRAM访问要计算的数据,所有要计算的数据,都要先从HBM拷贝到SRAM。这点和CPU架构一样,运算单元不能直接使用内存的数据,需要经过L1/L2缓存。
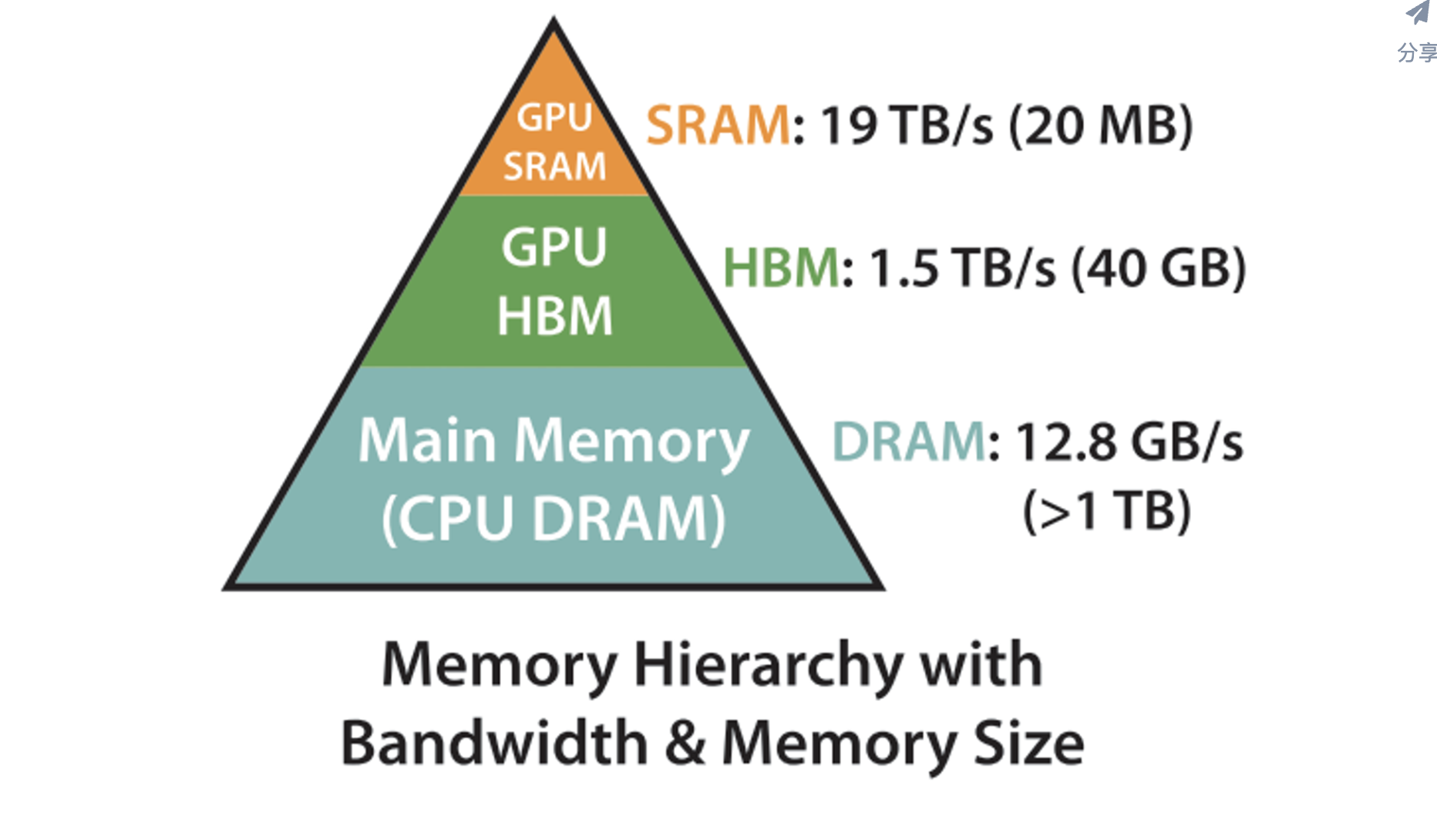
HMB的问题在于传输带宽低,在标准Attention中,影响运行速度最重要的因素便是HBM访问次数。
2. Flash Attention是如何优化的
Flash Attention 是一种高效的注意力计算算法,旨在解决传统的注意力机制(如自注意力)在计算资源上高昂的成本问题,尤其是在处理长序列时。它通过创新的内存访问模式和并行计算策略来显著加速注意力机制的执行,尤其是在大规模模型和长序列处理时。Flash Attention 最初由研究人员提出,专门优化了 Transformer 架构中的自注意力计算。
主要特点:
高效内存利用:传统的自注意力计算需要大量的内存和计算资源,尤其是在处理大批量长序列时。Flash Attention 通过优化内存访问和减少不必要的内存占用,提高了内存利用率,从而实现了加速。
并行计算:Flash Attention 采用了适合现代 GPU 计算架构的并行计算策略,减少了内存和计算瓶颈,使得注意力计算更加高效。
低精度计算:Flash Attention 利用低精度(例如半精度浮动点数 FP16)来进行计算,从而进一步提高计算速度和减少内存需求,同时几乎不影响模型性能。
序列长度无关:与传统注意力机制不同,Flash Attention 对于处理较长的序列时具有优势,因为它在计算复杂度和内存占用上具有较好的扩展性。
工作原理:
Flash Attention 的关键思想是将注意力的计算分解为多个高效的操作,并利用硬件加速(如 GPU)进行优化。它通过块化操作将注意力矩阵分割成较小的部分,以减少每次计算所需的内存量,同时保持高度的并行性。
a. 并行计算
Flash Attention 的另一个重要优化是在 GPU 上实现的并行计算。通过以下技术加速计算:
矩阵乘法优化:Flash Attention 通过改进的矩阵乘法来计算注意力分数。它通过分块(blockwise)计算,将大矩阵拆解为小矩阵,从而并行化计算过程。这种分块方式减少了计算时的依赖关系,可以同时计算多个块的注意力分数。
减少中间变量计算:在传统的注意力计算中,计算过程会生成多个中间变量(例如 Q、K、V 矩阵),然后再进行计算。Flash Attention 通过优化计算过程,将多个计算步骤合并,减少了中间变量的生成,从而减少了计算量和内存开销。
b. 局部矩阵乘法
Flash Attention 在实现上采用了局部矩阵乘法策略,特别是在计算 Q 与 K 的点积时,它通过直接计算一个小块的结果,并利用块内的并行计算来减少内存开销。最终的计算可以通过矩阵块之间的并行化来实现。
3. 如何使用
参考:
3.1 硬件需求
FlashAttention-2 硬件支持
Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100).
Turing GPUs 只能使用FlashAttention 1.x.